
选自 towardsdatascience
作者:Ma l Fabie
机器之心编译
参与:Panda
很多研究者和开发者都认为,初学神经网络时,最好的方法莫过于先自己动手训练一个模型。机器之心也曾推荐过很多不同开发者写的上手教程。本文同样是其中之一,数据科学家 Ma l Fabien 介绍了如何使用自己的博客文章训练一个和自己风格一样的简单语言生成模型。
在过去几个月的课程中,我在我的个人博客上写了 100 多篇文章。数量还是很可观的。然后我有了一个想法:
训练一个说话方式与我类似的语言生成模型。
更具体而言,是书写风格像我。这种方式能完美地阐释语言生成的主要概念、使用 Keras 的实现以及我的模型的局限性。
本文的完整代码见这个代码库:
https://github.com/maelfabien/Machine_Learning_Tutorials
在我们开始之前,我推荐一个我发现的很有用的 Kaggle Kernel 资源,可以帮助理解语言生成算法的结构:https://www.kaggle.com/shivamb/beginners-guide-to-text-generation-using-lstms
语言生成
自然语言生成(NLG)是一个以生成有意义的自然语言为目标的领域。
大多数情况下,内容是以单个词的序列的形式生成的。这是一个很宽泛的思想,大致工作方式如下:
训练一个模型来预测一个序列的下一个词
为训练好的模型提供一个输入
迭代 N 次,使其生成后面的 N 个词
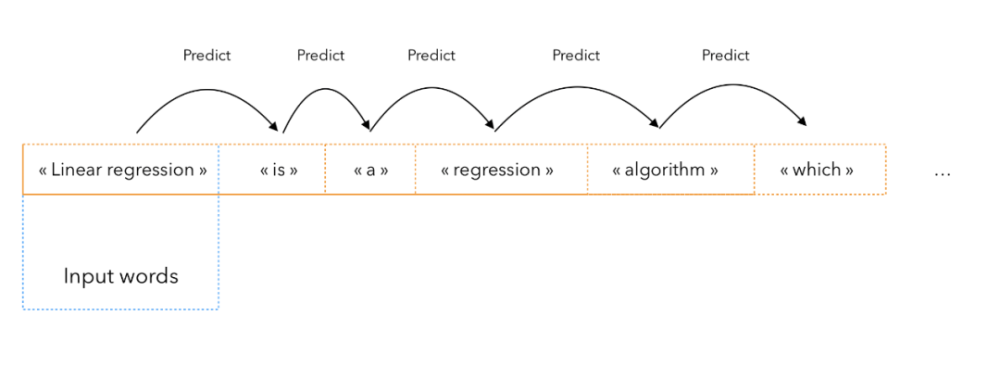
序列预测过程
1.创建数据集
第一步是构建一个数据集,让我们之后可以基于其构建网络,因此这个数据集需要构建成可被该网络理解的形式。首先导入以下软件包:
a.载入数据
我写的每篇文章的文件头都使用了以下模板:

这是我们通常不希望出现在我们的最终数据集中的内容。我们想要关注的是文本本身。
每一篇文章都是一个单独的 Markdown 文件。文件头基本上包含的是标题、标题图片等信息。
b. 句子 token 化
然后,打开每篇文章,将每篇文章的内容都附加到一个列表中。但是,因为我们的目标是生成句子,而非整篇文章,所以我们需要将每篇文章都分割成句子列表,并将每个句子附加到列表「all_sentences」。
总体而言,我们得到了略多于 6800 个训练句子。到目前为止的过程如下:

句子分割
c. 创建 n-gram
然后,创建一起出现的词的 n-gram。为了实现这一目标,我们需要:
在语料库上使用一个 token 化程序,为每个 token 都关联一个索引
将语料库中的每个句子都分解为一个 token 序列
将一起出现的 token 序列保存起来
下图展示了这个过程:

创建 N-gram
我们来实现它吧。我们首先需要使用 token 化程序:
变量 total_words 包含使用过的不同词的总数。这里是 8976。然后,对于每个句子,获取对应的 token 并生成 n-gram:
token_list 变量包含以 token 序列形式存在的句子:
然后,n_gram_sequences 创建 n-gram。它从前两个词开始,然后逐渐添加词:
d. 填充
现在我们面临着这样一个问题:并非所有序列都一样长!我们如何解决这个问题呢?
我们将使用填充(padding)。填充是在变量 input_sequences 的每一行之前添加 0 构成的序列,这样每一行的长度便与最长行一样了。

填充的图示
为了将所有句子都填充到句子的最大长度,我们必须先找到最长的句子:
我的情况是最大序列长度为 792。好吧,对于单句话来说,这一句确实相当长!因为我的博客包含一些代码和教程,所以我估计这一句实际上是 Python 代码。我们绘制一个序列长度的直方图来看看:

序列长度
确实仅有非常少的样本的单个序列超过 200 个词。那么将最大序列长度设置为 200 如何?
这会返回类似这样的结果:
e. 分割 X 和 y
现在我们有固定长度的数组了,其中大多数在实际的序列之前都填充了 0。那么,我们如何将其转换成一个训练集?我们需要分割 X 和 y!要记住,我们的目标是预测序列的下一个词。因此,我们必须将最新的 token 之外的所有 token 都视为 X,而将那个最新的 token 视为 y。

分割 X 和 y
用 Python 执行这个操作非常简单:
现在我们可以把这个问题视为一个多类分类任务。首先,我们必须对 y 进行 one-hot 编码,得到一个稀疏矩阵,该矩阵在对应于该 token 的一列包含一个 1,其它地方则都是 0。

在 Python 中,使用 Keras Utils 的 to_categorial:
y = ku.to_categorical(y, num_classes=total_words)
现在,X 的形状为 (164496, 199),y 的形状为 (164496, 8976)。
现在我们有大约 165000 个训练样本。X 的列宽为 199,因为其对应于我们允许的最长序列长度(200-1,减去的 1 是要预测的标签)。y 有 8976 列,对应于词汇表所有词的一个稀疏矩阵。现在,数据集就准备好了!
2. 构建模型
我们将使用长短期记忆网络(LSTM)。LSTM 有一个重要优势,即能够理解在整个序列上的依赖情况,因此,句子的起始部分可能会影响到所要预测的第 15 个词。另一方面,循环神经网络(RNN)仅涉及对网络之前状态的依赖,且仅有前一个词有助于预测下一个词。如果选用 RNN,我们很快就会失去上下文语境,因此选择 LSTM 似乎是正确的。
a. 模型架构
因为训练需要非常非常非常非常非常的时间(不是开玩笑),所以我们就创建一个简单的「1 嵌入层+1 LSTM 层+1 密集层」的网络:
首先,我们添加一个嵌入层。我们将其传递给一个有 100 个神经元的 LSTM,添加一个 dropout 来控制神经元共适应(neuron co-adaptation),最后添加一个密集层(dense layer)收尾。注意,我们仅在最后一层上应用一个 softmax 激活函数,以获得输出属于每个类别的概率。这里使用的损失是类别交叉熵,因为这是一个多类分类问题。
下面汇总了该模型的情况:

模型情况总览
b. 训练模型
现在我们终于准备好训练模型了!
然后模型的训练就开始了:
在一个 CPU 上,单个 epoch 耗时大约 8 分钟。在 GPU 上(比如 Colab),你应该修改所使用的 Keras LSTM 网络,因为它不能被用在 GPU 上。你需要的是这个:
我在训练几步之后就会停一下,以便采样预测结果,以及根据交叉熵的不同值来控制模型的质量。
下面是我观察到的结果:

3. 生成句子
读到这里,下一步就可以预料了:生成新句子!要生成新句子,我们需要将同样的变换应用到输入文本上。我们构建一个循环来迭代生成下一个词一定次数:
当损失大约为 3.1 时,下面是使用「Google」作为输入而生成的句子:
Google is a large amount of data produced worldwide
这没什么真正的含义,但它成功地将 Google 与大量数据的概念关联到了一起。这是非常了不起的,因为这只依靠词的共现,并没有整合任何语法概念。
如果模型的训练时间更长一些,将损失降到了 2.5,那么给定输入「Random Forest」,会得到:
Random Forest is a fully managed service distributed designed to support a large amount of startups vision infrastructure
同样,生成的东西没什么意义,但其语法结构是相当正确的。
损失在大约 50 epoch 后就收敛了,且从未低于 2.5。
我认为这是由于这里开发的方法的局限性:
模型仍然非常简单
训练数据没有理应的那样整洁
数据量非常有限
话虽如此,我认为结果还是挺有意思的,比如训练好的模型可以轻松地部署到 Flask WebApp 上。
总结
我希望这篇文章是有用的。我尝试阐释了语言生成的主要概念、难题和局限。相比于本文中讨论的方法,更大型的网络和更好的数据肯定有助于改善结果。








